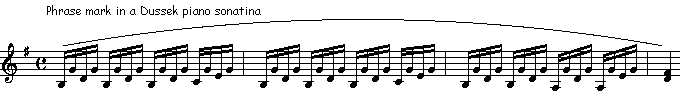Answer:
A slur is indicated by a curvy line that begins at the first note of the slur group and continues to the last note. On a bowed instrument the bow continues in the same direction on a slur, as much as possible; on a wind instrument the note similarly continues without being rearticulated; a singer stays on the same syllable. On a keyboard instrument the performer just tries to join those notes smoothly together.
A "tie" is a similar curved line that joins two notes of the same pitch. The second note is a continuation of the first:
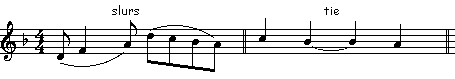
A slur may be hard to distinguish from a "phrase mark," which looks like a slur but may cover a longer passage and really just indicates that this is one phrase, like a phrase in spoken language. Some writers, such as Gardner Read in his authoritative text "Music Notation," treat the two terms as more or less equivalent. Personally I prefer to distinguish between slurs and phrase marks: the bowing or tonguing of slurred notes is pretty specific, as above, but a phrase may necessarily include some changes of bow, etc. It depends on the instrument for which the music is intended. In piano music you may see a "slur," actually a phrase mark, that extends over several measures of common time - too much for one bow or one breath. Actually I think phrase marks are sometimes a little fussy; a musician should be able to find phrases without being guided to them. But a composer or editor may not have confidence that the performer will find the intended phrase, so the mark can be considered educational.